Stability AI 持续发布多款开源基础模型,涵盖图像、视频、音频、3D 等领域,降低前沿 AI 的使用门槛,为全球开发者与创作者提供自由扩展的底层能力。
以 Stable Diffusion 系列模型为代表,轻松将文本描述转化为高分辨率、细节丰富的图像,支持风格迁移、图像编辑及条件控制,输出质量达到行业顶尖水准。
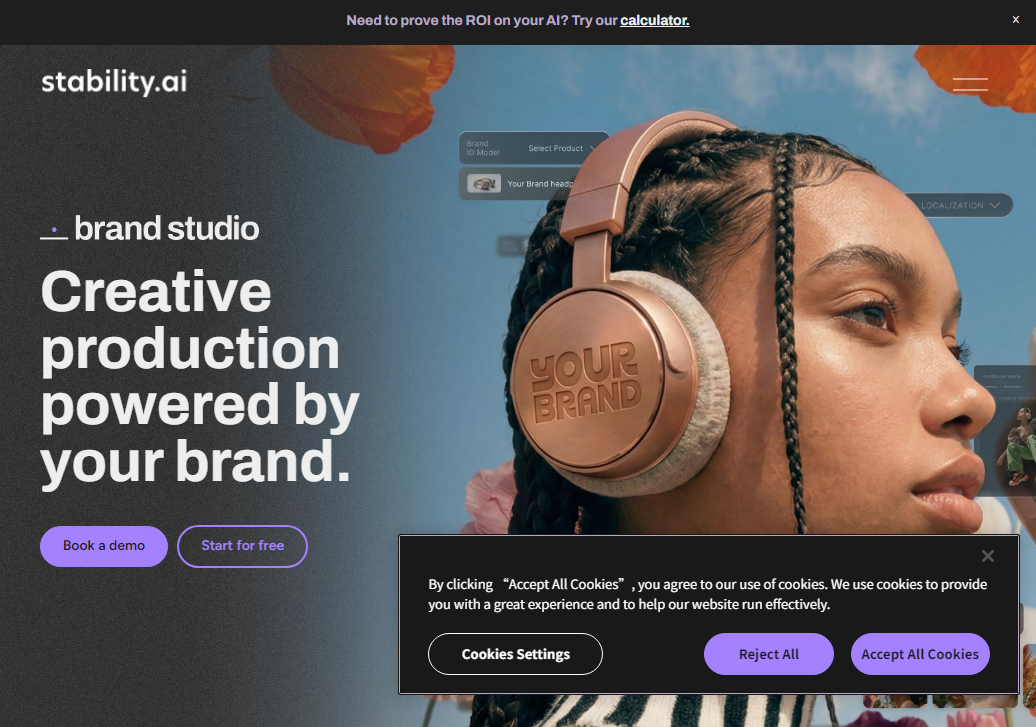
统一平台提供了图像、视频(Stable Video Diffusion)、3D(Stable 3D)、音频(Stable Audio)等多模态生成与编辑能力,满足从个人创作者到企业级应用的多元化需求。
Emad Mostaque 在英国伦敦创立 Stability AI,最初专注通用人工智能研究,利用开源协作与分布式计算推动多模态模型开发。
8 月,Stability AI 联合多位研究者发布 Stable Diffusion 1.4,一个基于潜在扩散模型的文本到图像生成模型,采用开源许可发布,引发全球关注。10 月,公司宣布完成 1.01 亿美元种子轮融资,由 Coatue Management 和 Lightspeed Venture Partners 领投,估值突破 10 亿美元。
推出 Stable Diffusion 2.0 及后续 2.1 版本,加入更强调创作者权益的协议。4 月发布 Stable Diffusion XL 测试版,提升图像分辨率与构图质量。5 月推出音频生成工具 Stable Audio,支持文字生成音乐与音效。7 月正式发布 Stable Diffusion XL 1.0,同期引入 DreamStudio 网页端编辑功能。12 月,公司进行首次裁员,调整组织结构以聚焦核心产品。
2 月发布 Stable Diffusion 3.0 预览版,采用新型扩散 Transformer 架构,大幅改善文字渲染与多主体生成能力。6 月开源 Stable Diffusion 3 Medium(2.5B 参数),面向消费级 GPU 提供高质量生成。同月推出图像生成 API 和 Stability AI Platform,让开发者直接调用模型。下半年公司经历管理层变动,多位高管离职,并关闭部分非核心业务线,同时发布 Stable Video Diffusion 1.1 巩固视频生成赛道。
年初推出 Stable Diffusion 3.5 系列,支持更精细的风格控制和构图引导。更新 Stable Audio 2.0,提供最长 45 秒的高保真音乐生成。公司转向“开源核心 + 商业许可”双轨模式,部分高级模型仅通过 API 或企业订阅提供,以平衡社区需求与商业可持续性。